♣ Double Linked List
Double Linked List adalah bentuk konsep data sturcture yang serupa dengan Single Linked List dimana elemen disimpan dengan posisi terurut. Dengan menggunakan Double Linked List operasi yang dilakukan akan lebih efisien dibandingkan menggunakan Single Linked List.
Perbedaan Double dan Single Linked List yang utama adalah pada jumlah pointer yang dimiliki. Double memiliki 2 pointer yang biasa disebut Next dan Prev sedangkan Single hanya memiliki 1 pointer Next saja.
Operasi pada Double Linked List juga kurang lebih sama seperti Single Linked List yaitu traversing, inserting, searching, dan deleting.
Insert dan Delete = dapat dilakukan diawal, diakhir, sesudah Node, atau sebelum Node.

Gambar 1 : Kita gunakan untuk membuat struct Node dan 2 pointer untuk menunjuk Head (data pertama kita) dan Tail (data terakhir kita).

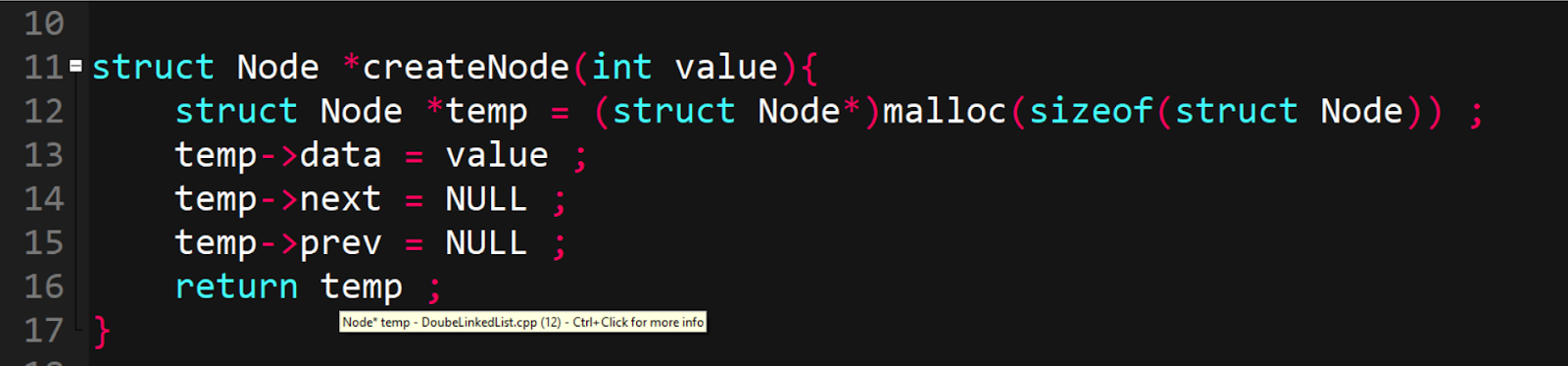
Gambar 2 : Membuat suatu fungsi untuk membuat Node baru.

Gambar 3 : Mulai membuat fungsi untuk Insert. pushHead -> untuk insert pada data diawal. pushTail -> untuk insert data pada data terakhir.
 Gambar 4 : Membuat fungsi pushMid. Fungsi ini akan menghasilkan Linked List dengan data terurut.
Gambar 4 : Membuat fungsi pushMid. Fungsi ini akan menghasilkan Linked List dengan data terurut.

Gambar 5 : Berisi fungsi display (untuk menampilkan data), fungsi popHead (untuk menghapus data paling depan), fungsi popTail (untuk menghapus data paling akhir).
 Gambar 6 : Berisi fungsi popMid (untuk menghapus data berdasarkan keinginan user).
Gambar 6 : Berisi fungsi popMid (untuk menghapus data berdasarkan keinginan user).
♠ Hash Table
Hash Table adalah bentuk data structure dimana elemen data kita akan dimapping kedalam suatu array berdasarkan key yang dimiliki oleh data.
Hash Table kita gunakan untuk mempercepat proses seraching hingga dapat mencapai O(1). Ada beberapa cara yang dapat kita lakukan yaitu dengan menggunakan Array (memanfaatkan indexing) dan Hash Table. Array kurang dianjurkan karena dapat menyebabkan store terbuang banyak.
Tujuan digunakan Hash Table adalah untuk memperkecil range Array kita sehingga searching menjadi lebih cepat.
Pada Hash Table akan dijumpai beberapa istilah baru seperti :
1. Collision = jika diartikan dalam bahasa Indonesia artinya bertubrukan. Maksudnya collision disini adalah kondisi dimana beberapa elemen menunjuk pada alamat memory yang sama.
2. Hash Function = fungsi yang berupa formula matematika. Fungsi ini akan digunakan untuk menghasilkan key. Key ini nanti akan digunakan untuk memposisikan data kita kedalam Array. Perlu diingat bahwa tidak ada Hash Function yang dapat mengatasi collison 100%.
Ada beberapa macam Hash Function antara lain :
☻Divison Method = x mod M (x = value data kita, M = prime numbers)
☻Multiplication Method = m (x A mod 1)
m = ukuran table kita
x = value data kita
A = konstanta (biasa digunakan A = 0.618033 -> dianjurkan oleh Knuth)
☻ Mid Square = mengkuadratkan value kita lalu mengambil nilai tengah
☻Folding Method = kita membagi angka sesuai ukuran table, lalu menjumlahkannya.Pada akhir fungsi di modulo dengan size table
• Cara menangani collision
1. Open Addressing
adalah metode mengatasi collide dimana kita akan mengkomputasi ulang key sehingga mendapatkan posisi baru yang kosong. Jika semua posisi sudah penuh maka masuk ke kondisi Overflow.
Open Addressing ini memiliki banyak macam antara lain linear probing, quadratic probing, double hashing, dan rehashing.
◘ Linear Probing = kita akan mencari posisi baru dengan menggeser key. Semisal key yang didapatkan adalah 5. Namun ternyata index 5 sudah ditempati, jika kondisi seperti ini key akan +1 menjadi 6 lalu dilakukan pengecekan lagi.
◘ Quadratic Probing =

◘ Double Hashing = kita akan melakukan hashing sebanyak 2 kali.

◘ Rehashing = jika table kita hampir full maka performa nya akan melambat. Untuk mengatasi hal ini kita bisa melakukan rehashing dengan cara menampung data kita kedalam table yang lebih besar. Sebelum ditampung kita harus melakukan hashing lagi terhadap data kita yang baru.
2. Chaining
Pada konsep chaining ini kita akan menggunakan Single Linked List. Chaining dilakukan ketika ada collision. Location awal akan menjadi head, jika location awal ini bernilai NULL artinya belum ada data pada array tsb.
• Penerapan Hash Table antara lain :
1. Driver License
2. File Signature
3. Gameboards
4. Graphics
5. CD Databases
6. Sparse Matrix
7. Hashing pada Block Chain
Pada Block Chain seperti Cryptocurrency banyak digunakan konsep Hashing. Contohnya pada setiap adanya transaksi, transaksi ini akan di Hashing. Hashing akan menghasilkan fixed length pada output. Tidak peduli seberapa panjang atau pendek input kita, length dari output akan tetap sama. Contohnya adalah enkirpsi SHA-256 (Security Hash Algorithm - 256)
Source : https://www.youtube.com/watch?v=rcNg9KsXuMc
Contoh :

Gambar 1 = Berisi Struct declaration untuk membuat Hash Table dengan konsep separate chaining. Disitu juga terlihat fungsi hashKey yang berguna untuk mendapatkan key dari data kita.

Gambar 2 = Berisi fungsi untuk membuat Node baru dan fungsi untuk menambahkan data kedalam Hash Table kita

Gambar 3 = Fungsi untuk menghapus data pada Hash Table kita.Dalam fungsi ini kita juga sudah menerapkan searching secara tidak langsung.

Gambar 4 = Fungsi untuk menampilkan data pada Hash Table kita.
Double Linked List adalah bentuk konsep data sturcture yang serupa dengan Single Linked List dimana elemen disimpan dengan posisi terurut. Dengan menggunakan Double Linked List operasi yang dilakukan akan lebih efisien dibandingkan menggunakan Single Linked List.
Perbedaan Double dan Single Linked List yang utama adalah pada jumlah pointer yang dimiliki. Double memiliki 2 pointer yang biasa disebut Next dan Prev sedangkan Single hanya memiliki 1 pointer Next saja.
Operasi pada Double Linked List juga kurang lebih sama seperti Single Linked List yaitu traversing, inserting, searching, dan deleting.
Insert dan Delete = dapat dilakukan diawal, diakhir, sesudah Node, atau sebelum Node.


Gambar 3 : Mulai membuat fungsi untuk Insert. pushHead -> untuk insert pada data diawal. pushTail -> untuk insert data pada data terakhir.


Gambar 5 : Berisi fungsi display (untuk menampilkan data), fungsi popHead (untuk menghapus data paling depan), fungsi popTail (untuk menghapus data paling akhir).

♠ Hash Table
Hash Table adalah bentuk data structure dimana elemen data kita akan dimapping kedalam suatu array berdasarkan key yang dimiliki oleh data.
Hash Table kita gunakan untuk mempercepat proses seraching hingga dapat mencapai O(1). Ada beberapa cara yang dapat kita lakukan yaitu dengan menggunakan Array (memanfaatkan indexing) dan Hash Table. Array kurang dianjurkan karena dapat menyebabkan store terbuang banyak.
Tujuan digunakan Hash Table adalah untuk memperkecil range Array kita sehingga searching menjadi lebih cepat.
Pada Hash Table akan dijumpai beberapa istilah baru seperti :
1. Collision = jika diartikan dalam bahasa Indonesia artinya bertubrukan. Maksudnya collision disini adalah kondisi dimana beberapa elemen menunjuk pada alamat memory yang sama.
2. Hash Function = fungsi yang berupa formula matematika. Fungsi ini akan digunakan untuk menghasilkan key. Key ini nanti akan digunakan untuk memposisikan data kita kedalam Array. Perlu diingat bahwa tidak ada Hash Function yang dapat mengatasi collison 100%.
Ada beberapa macam Hash Function antara lain :
☻Divison Method = x mod M (x = value data kita, M = prime numbers)
☻Multiplication Method = m (x A mod 1)
m = ukuran table kita
x = value data kita
A = konstanta (biasa digunakan A = 0.618033 -> dianjurkan oleh Knuth)
☻ Mid Square = mengkuadratkan value kita lalu mengambil nilai tengah
☻Folding Method = kita membagi angka sesuai ukuran table, lalu menjumlahkannya.Pada akhir fungsi di modulo dengan size table
• Cara menangani collision
1. Open Addressing
adalah metode mengatasi collide dimana kita akan mengkomputasi ulang key sehingga mendapatkan posisi baru yang kosong. Jika semua posisi sudah penuh maka masuk ke kondisi Overflow.
Open Addressing ini memiliki banyak macam antara lain linear probing, quadratic probing, double hashing, dan rehashing.
◘ Linear Probing = kita akan mencari posisi baru dengan menggeser key. Semisal key yang didapatkan adalah 5. Namun ternyata index 5 sudah ditempati, jika kondisi seperti ini key akan +1 menjadi 6 lalu dilakukan pengecekan lagi.
◘ Quadratic Probing =
◘ Rehashing = jika table kita hampir full maka performa nya akan melambat. Untuk mengatasi hal ini kita bisa melakukan rehashing dengan cara menampung data kita kedalam table yang lebih besar. Sebelum ditampung kita harus melakukan hashing lagi terhadap data kita yang baru.
2. Chaining
Pada konsep chaining ini kita akan menggunakan Single Linked List. Chaining dilakukan ketika ada collision. Location awal akan menjadi head, jika location awal ini bernilai NULL artinya belum ada data pada array tsb.
• Penerapan Hash Table antara lain :
1. Driver License
2. File Signature
3. Gameboards
4. Graphics
5. CD Databases
6. Sparse Matrix
7. Hashing pada Block Chain
Pada Block Chain seperti Cryptocurrency banyak digunakan konsep Hashing. Contohnya pada setiap adanya transaksi, transaksi ini akan di Hashing. Hashing akan menghasilkan fixed length pada output. Tidak peduli seberapa panjang atau pendek input kita, length dari output akan tetap sama. Contohnya adalah enkirpsi SHA-256 (Security Hash Algorithm - 256)
Source : https://www.youtube.com/watch?v=rcNg9KsXuMc
Contoh :

Gambar 1 = Berisi Struct declaration untuk membuat Hash Table dengan konsep separate chaining. Disitu juga terlihat fungsi hashKey yang berguna untuk mendapatkan key dari data kita.

Gambar 2 = Berisi fungsi untuk membuat Node baru dan fungsi untuk menambahkan data kedalam Hash Table kita

Gambar 3 = Fungsi untuk menghapus data pada Hash Table kita.Dalam fungsi ini kita juga sudah menerapkan searching secara tidak langsung.

Gambar 4 = Fungsi untuk menampilkan data pada Hash Table kita.
Comments
Post a Comment